Automated table ingestion with Databricks DLT
How you can use Databricks DLT and AutoLoader to automatically ingest datasets without writing additional code for each one. Speed up getting data into the platform so you can focus on the cool stuff!
DATABRICKSAUTOMATIONDELTA LIVE TABLES
Dian Germishuizen
6/23/20245 min read


Hello there!
My name is Dian Germishuizen, and today I want to show you something cool I did in Databricks this week.
I had to figure out: “How do I import many datasets into Databricks without having to hard code the statements to import each one and give each a list of columns?”.
This is a common frustration for companies because spending time on repetitive tasks is not a great use of a person's time. Especially if you are on a tight deadline to deliver something.
Luckily, Databricks Delta Live Tables (or DLT for short) can save us a lot of time and effort here!
DLT allows you to define a python function that will create a DLT table based on parameters you provide it at run time. You can then create a list of the tables you want to generate and the path in cloud storage where the data resides to import it. Then just loop over the list and let DLT do its magic!
But before I jump straight into showing you how this magic works, let me give a quick 101 overview of what DLT is, and why you would consider it for your data solution.
What is DLT ?
Delta Live Tables (or DLT) is a declarative ELT framework in Databricks.
You can use it for batch data processing or even streaming.
You use python or SQL to define a query that will produce the target table you want, Then DLT can manages the orchestration, cluster management, monitoring, data quality and even performs error handling for you.
The query you define can read from external locations like cloud storage, which is what I am going to be doing, or from Delta tables in Databricks, or other tables you created inside the same DLT pipeline.
This is where the real power of DLT comes from.
If you define a bronze layer table that reads from cloud storage, you can define a silver layer table that reads from the bronze layer table to perform whatever transformations you want at this stage, then also push the data to a gold layer table with all your business logic added.
This is not too different from a normal workflow so far. However, when I tell DLT to use the queries I created in a notebook to process the data, I don’t have to manually tell it which table to process first and what the dependency mapping looks like between them.
The fact that the gold table reads from silver, and the silver reads form bronze is enough information for DLT to automatically sequence the loads for me.
This provides many benefits to the data pipeline creation and execution process, including
Less time required for the developer to set up the orchestration of table generation.
Less time to maintain that same orchestration if changes are needed later.
The downstream tables can start executing as soon as all its upstream dependencies are done processing (if there are enough resources available on the cluster of course.), reducing the overall time it takes to process everything.
The Auto Loader can automatically perform the logic needed to only process new or changed files provided in the source location, again saving development time and reducing change of errors.
For non-streaming tables in the gold layer where you do aggregation, you can incrementally update the data in the target table for only those sections that are affected by changes in the source table. This does require the Change Feed to be enabled on your source table, but this is very easy and doesn’t add much overhead to the table itself. This is something I want to cover in the future as well.
That sounds pretty good to me !
Automated Table Generation
So, back to the dynamic table generation, and why is that going to save even more time than DLT saves by default!
Normally, if I wanted to import 5 datasets from cloud storage using DLT, I would have to manually defined the query for each one, with the columns to include and where to get the source data from.
Five queries are not that bad, but what happens when you are migrating a customer to Databricks, and they have 2,000 + tables to import. Yeah, not fun.
I can use Python instead to automatically generate the bronze layer tables for me, simply by providing a template table structure and the list of table names and source data locations for each.
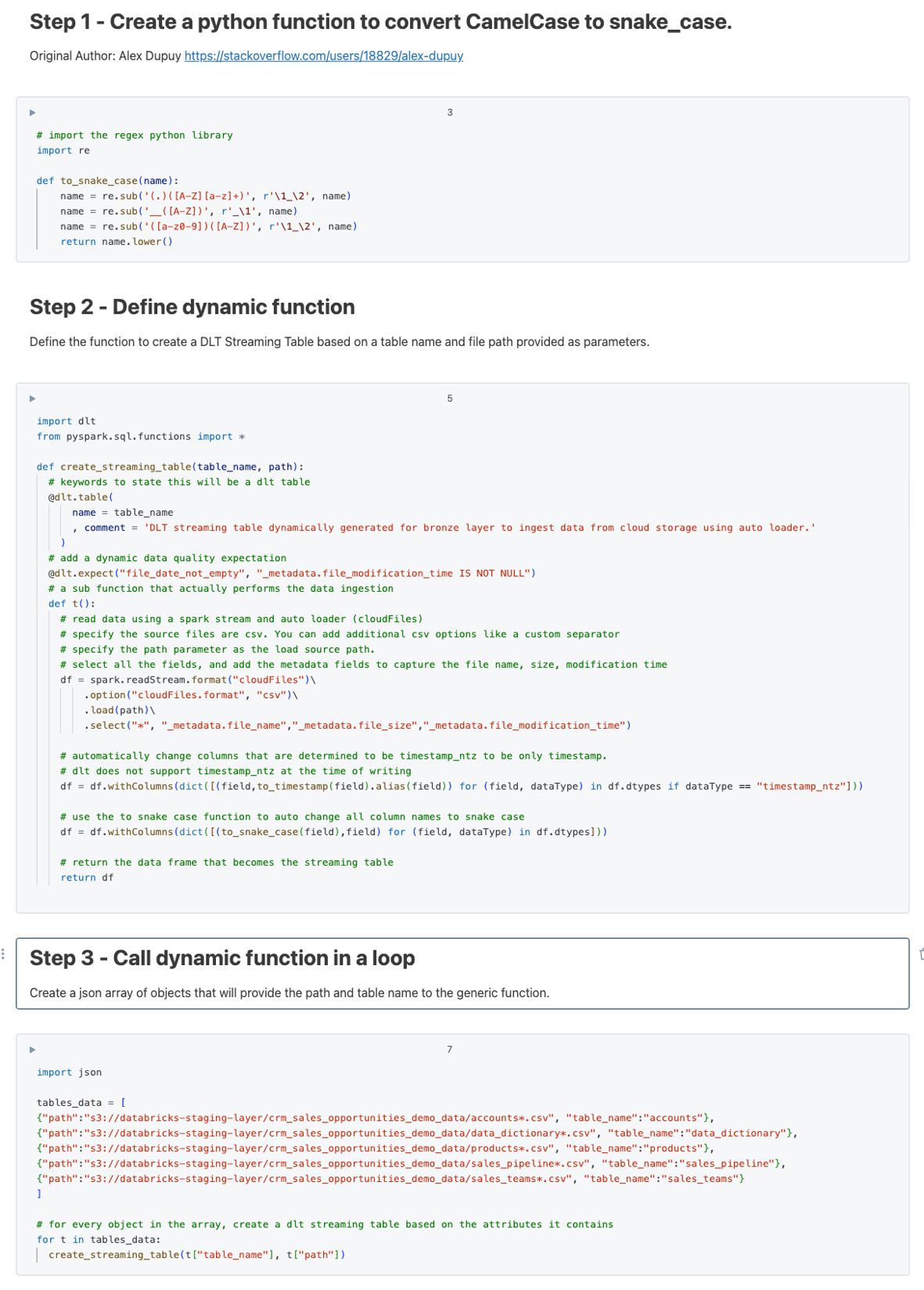
The actual code will be available on the desktop version, on mobile the image above is the best way to add it...
Let’s go over each line to understand what it does and how it works:
The section about snake case you can ignore, that's something for another time.
Lets look at this create_streaming_table function.
It takes a table_name and path as parameter. This is important because this is what allows it to create multiple different tables at once.
The @dlt.table keyword is what tells Databricks this is a dlt table.
We pass through the table_name parameter so it knows what the target name needs to be.
The comment is optional but is a good practice to keep. Its like self documenting the solution.
The @dlt.expect is also optional, I just added it to show how the data quality element can also fit into this solution.
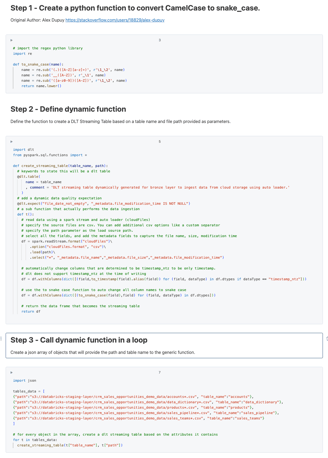
This secondary inner function is where all the logic sits.
Here you use the standard spark.readStream command to indicate this needs to be a streaming table.
You do all the standard things needed to read files from cloud storage
You tell it to use cloudFiles and what file format to expect
Here we use the second parameter, the path to the location in cloud storage where the source files sit.
Then lastly, again an optional item I like to add, is the metadata fields. This is very useful for troubleshooting later because you can save the file name and size where the data came from, and when last it was modified.
The last two withColumns sections are also not for today, I’ll do dedicated videos on that later. In short, you can automatically change the data types and column names for columns at run time !
Lastly, we need to define the list of tables and where the source files sit for the pipeline.
For easy of use I just used a hard coded JSON Array, but this can be stored in a table as well and read from there.
Then you just loop over the records and call the function for each one.
What does it look like in action ?
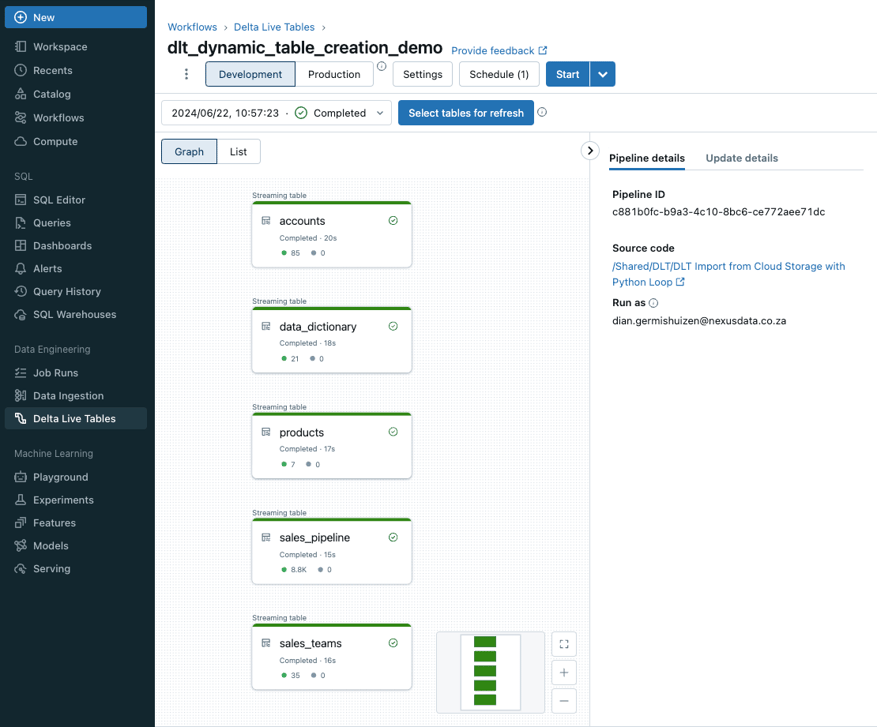
Only the one notebook I created was added to the DLT pipeline. All five tables in the list have been defined, and if I navigate to the catalog and schema I specified, we can see the tables and the data, nice!
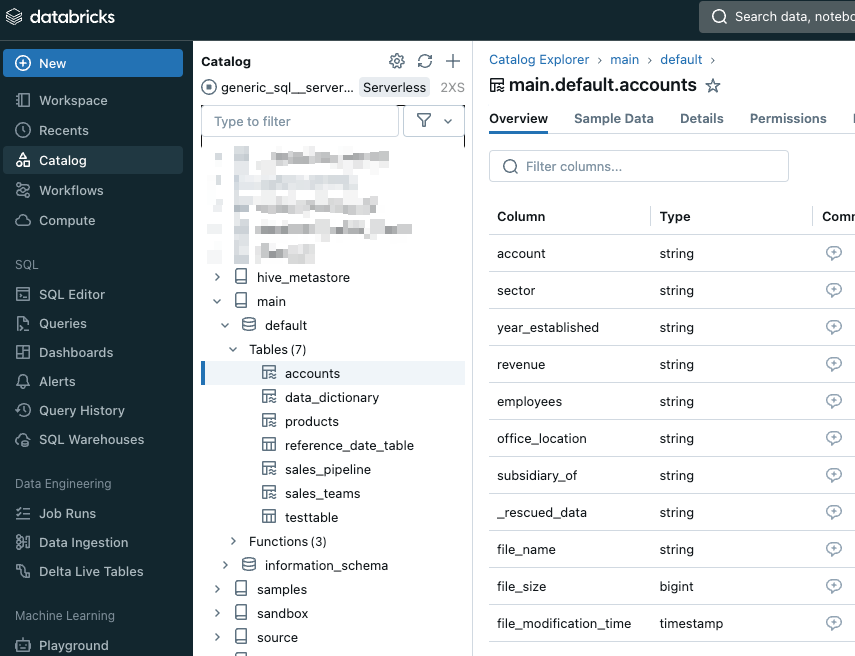
So why does this matter ?
Like I mentioned earlier, it's all about efficiency in resource utilisation.
If I can take 1 hour to write one notebook that will loops over all the datasets I need to ingest, I can get thousands of datasets into Databricks in less than a day. This only really applies to the bronze layer, but that's still a big chunk of the process.
That is pretty powerful and will save so much time in data projects!
Let me know your thoughts in the comments, and send me your suggestions on what you think would be interesting to cover next!
That's all folks



Social
All content on this website is either created by us or is used under aa free to use license.. We create the posts here to help the community as best as we can. It doesn't mean we are always correct, or the methods we show here are the best. We all change and learn as we grow, so if you see something you think we could have done better, please reach out! Let's share the knowledge and be kind to each other!
DIAN
GDG
FRANS